
Pourquoi il faut lire le Red Book du DDD (Domain Driven Design) !
Après avoir entendu plusieurs développeurs dire du bien du DDD, voilà plusieurs jours que j’ai entamé la lecture du Red Book (Implementing Domain-Driven Design). Ne pouvant résister à échanger sur cette magnifique lecture, je vous propose d’essayer de vous convaincre et de vous inciter à commencer cette lecture plus qu’intéressante.
L’objectif est ici de vous expliquer ce que j’ai compris des concepts de base du DDD, à quoi ça sert et comment ça marche. Loin de moi l’idée d’avoir suffisamment d’expérience pour pouvoir vous dresser une liste des avantages et des inconvénients. Juste vous donner envie.
Définir un langage commun (ubiquitous language) entre les développeurs et les experts métier
Le principe du DDD (Domain Driven Design) est de faire partager un même vocabulaire (ubiquitous language) dans toutes les divisions d’une société, et ce en incluant intégralement les experts métier et les développeurs : il adresse ainsi le fameux problème de traduction de l’informatique.
En effet, au siècle dernier, mes mentors m’expliquaient que l’informatique visait essentiellement à traduire un besoin (exprimé par des experts métier) vers du langage machine (le code). C’est toujours le cas aujourd’hui. L’informatique automatise des traitements dans l’objectif de faire de gagner du temps et de la qualité. Pour automatiser ces traitements, il faut pouvoir expliquer à la machine (ordinateur), dans son langage à elle, ce qu’elle doit faire. D’un point de vue presque philosophique, on peut dire que les développeurs sont des traducteurs car ils traduisent un besoin de traitement exprimé par un humain (l’expert métier) vers le langage de la machine (c.f. dessin suivant).
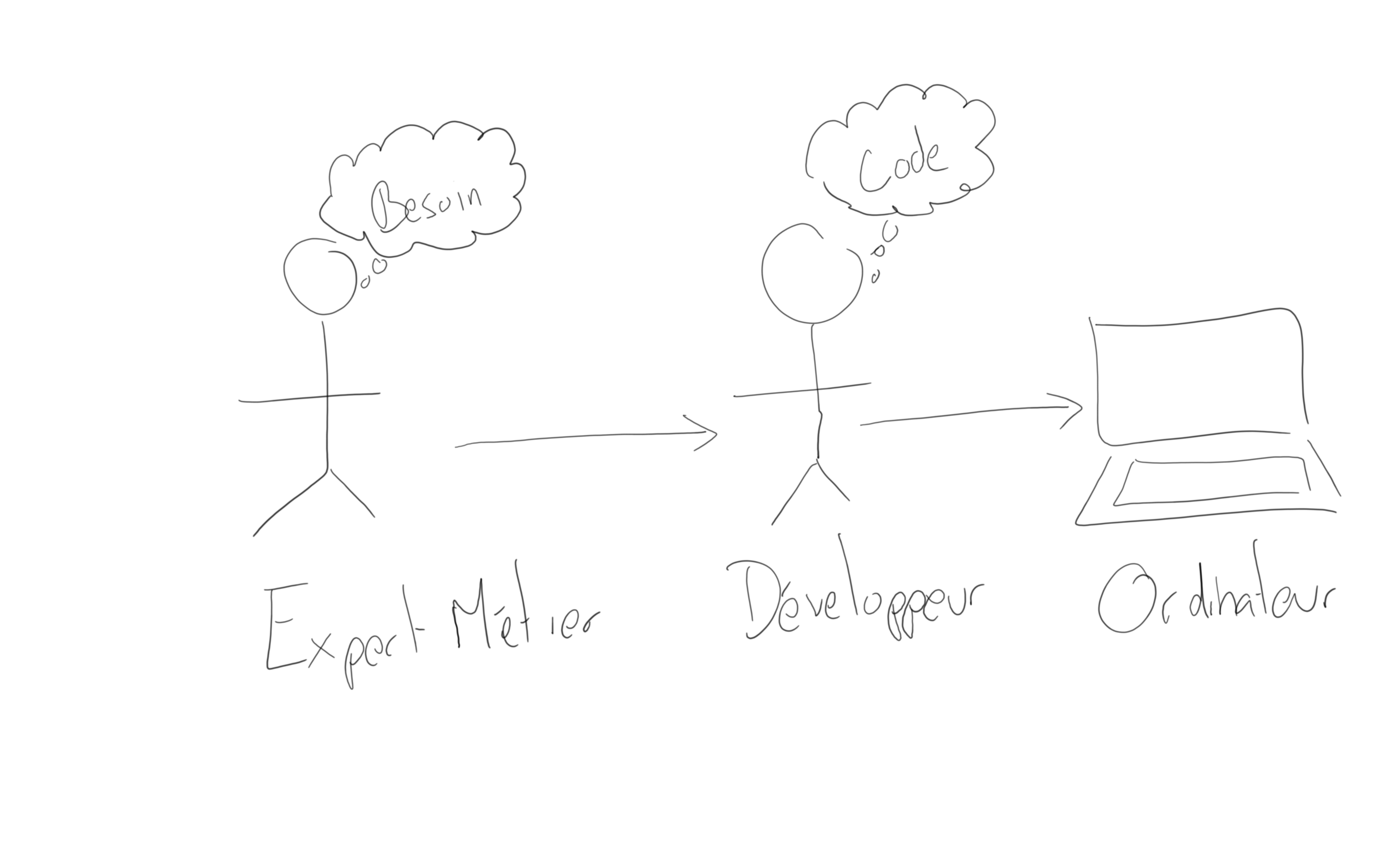
Il y en a eu des recherche et des trouvailles pour faciliter cette traduction. On peut citer les innombrables travaux pour améliorer les langages de programmation et les faire gagner en abstraction. Grâce aux langages de nouvelle génération, le développeur n’est plus obligé de parler le langage de la machine (l’assembleur), il dispose de son propre niveau d’abstraction, avec sa propre sémantique (variable, fonction, objet, etc.). Comme innovation, on doit aussi citer les méthodes agiles, qui permettent aux experts métier de se rapprocher des développeurs et ainsi de minimiser les risques d’incompréhension. Bref, en prenant (beaucoup) de hauteur, on peut dire que l’objectif de ces travaux est de minimiser le fossé qui existe entre l’expert métier et le développeur.
Pour autant le problème reste et demeure, à un moment, il faut traduire… et là, le DDD propose une nouvelle approche : que le développeur, dans son code, utilise des termes que l’expert métier connait et utilise ! Cela ne fait pas disparaître la traduction, car il faut bien que le développeur réalise le besoin de l’expert métier (et donc traduise), mais cela permet à l’expert métier et au développeur d’avoir le même langage.
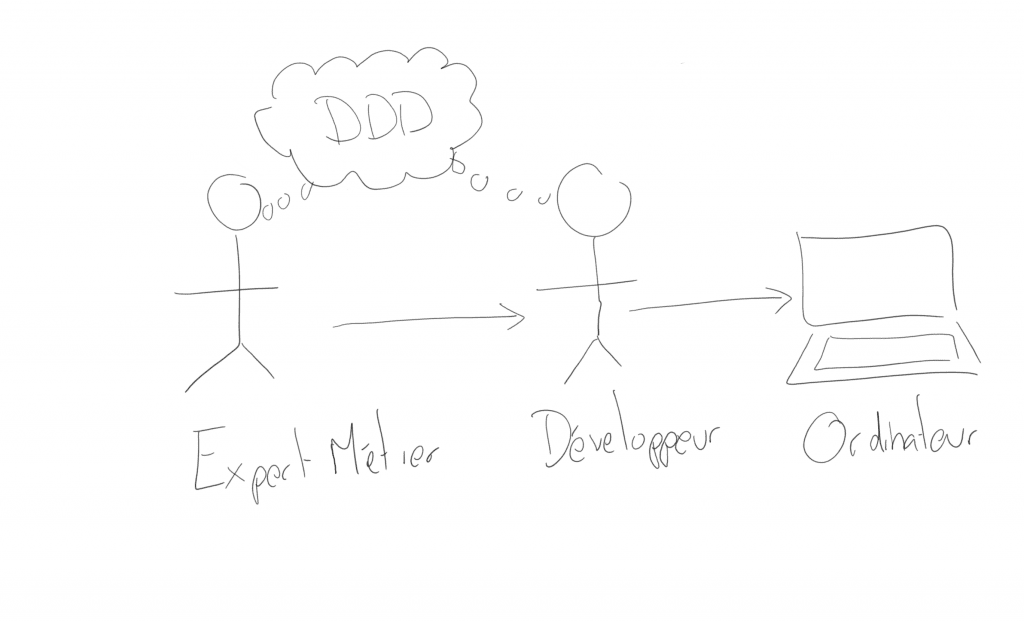
En fait, disposer d’un langage unique permet d’aligner le code avec le métier. Cela offre de nombreux avantages, tels qu’une bonne connaissance du métier par les développeurs et donc une implication plus importante, une bonne compréhension du code par le métier et donc une meilleure appréhension de son importance, une identification précise des parties du code qui sont dites “core business”, une meilleure agilité car on connait l’impact des modifications du code sur le métier, une meilleure estimation des coûts de maintenance, etc.
Et surtout, en finir avec l’amnésie du code
L’avantage le plus marquant (pour moi), très bien décrit dans le Red Book est que le DDD permet enfin d’en finir avec l’amnésie du code.
En effet, si aujourd’hui les besoins métiers sont de mieux en mieux traduits et s’ils sont bien reflétés dans le code source d’un logiciel, ce code source reste néanmoins très technique et sa lecture seule ne permet pas comprendre les besoins métiers sous-jacents (même en suivant les principe du Clean Code… trust me).
Le résultat est que le code source devient amnésique ; c’est-à-dire qu’il ne sait plus quel besoin métier il traite. L’inconvénient est que toute modification d’un code source amnésique entraîne irrémédiablement des sueurs froides, ne sachant pas mesurer leur impact sur le métier…
Prenons le code source suivant (extrait du Red Book). Ce code est la traduction d’un besoin exprimé par un expert métier, qui souhaite saisir des informations sur ses clients. Le bout de code montré permet de sauver un client (saveCustomer). Or, en lisant ce code, on ne sait pas du tout quel besoin métier il incarne. Est-ce la sauvegarde initiale ? La modification d’une propriété ? De toutes ?
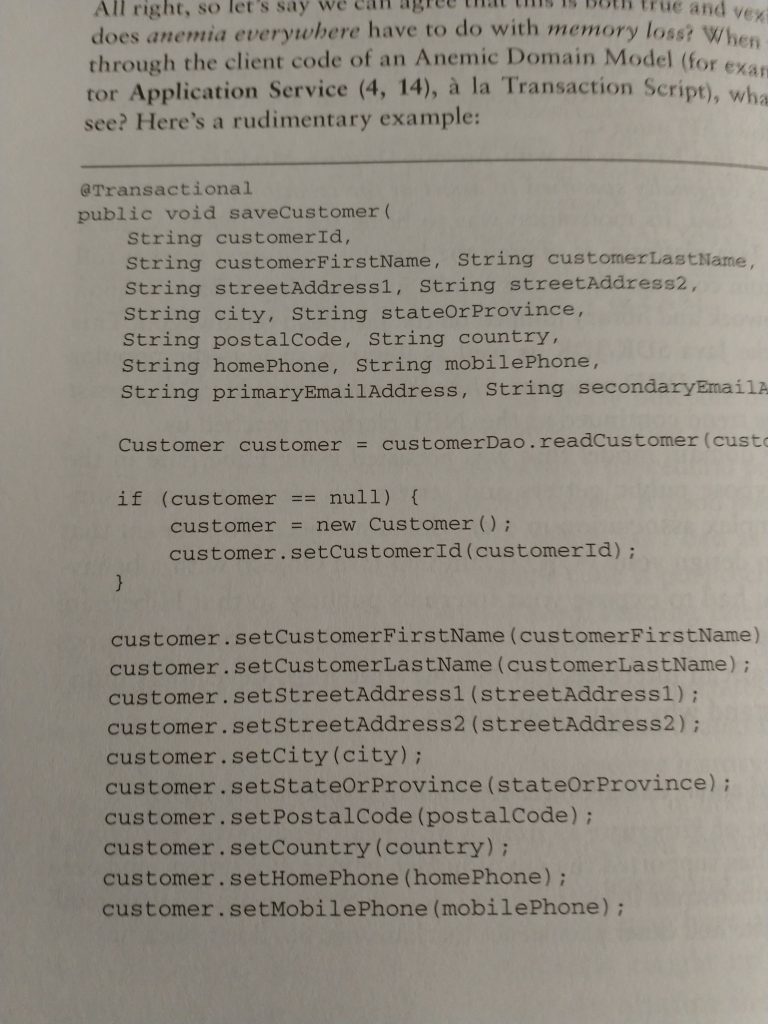
Ce code est donc amnésique car on ne sait pas le lier à un besoin métier. Changer ce code devient problématique, car on ne peut pas mesurer l’impact du changement sur les besoins métiers. Pire, il est impossible de cloisonner ce code à une sous-partie des besoins métier !
Si on avait suivi le DDD, les développeurs et les experts métiers partageraient le même vocabulaire (et il y a de fortes chances que les experts métier auraient refusé d’utiliser saveCustomer car c’est trop générique, trop technique, bref pas assez métier).
Prenons cet autre extrait de code (toujours dans le Red Book). On voit maintenant que le nom de la méthode est directement relié à un terme métier (changeCustomerPersonalName). On comprend alors que ce morceau de code est appelé quand on souhaite changer le nom d’un client. C’est un petit changement, qui pourtant fait toute la différence.

Des concepts, stratégies, méthodes pour définir ce langage commun
Si vous êtes convaincus de l’intérêt de l’approche, j’ai accompli 90% de mon objectif. Il me reste juste à vous convaincre de lire… l’intégralité du Red Book.
Dites vous que la réalisation de ce vocabulaire commun est un réel challenge. Inutile d’essayer de faire réunion sur réunion, afin d’arriver à un consensus sur un dictionnaire commun, cela serait un échec cuisant.
Et c’est bien là que le DDD prend tout son sens. Déjà, il insiste sur la définition de frontières dans la définition de votre vocabulaire commun. En effet, s’il est impossible de définir un seul et unique vocabulaire commun pour toute une société, il est par contre beaucoup plus malin de définir plusieurs petits vocabulaires communs, chacun centré sur un domaine particulier. Pour faire écho à cette approche, le DDD vous propose des concepts que sont le “context boundary” et autre “domain” et “core domain“.
Ensuite, le DDD va vous expliquer comment faire des passerelles entre vos différents petits vocabulaires et ainsi expliquer les relations qui peuvent exister entre ceux-ci. Par exemple, si vous utilisez une API qui est développée par une organisation externe, alors vous êtes clients du vocabulaire de cette API et vous êtes même dans une relation de Consommateur/Producteur. Si cela est central pour votre business, il serait certainement intéressant de préciser votre vocabulaire d’utilisation de cette API et de construire une sorte de surcouche (anticorruption layer).
Enfin, le DDD va beaucoup plus loin en vous proposant des stratégies, des méthodes et des patterns vous permettant de mettre en place l’approche sans tomber dans des pièges de conceptualisation. Le Red Book est une mine d’or de recettes qui marchent, mais aussi de retours d’expérience et d’exemples plus qu’intéressants.
En conclusion
Voilà c’est court mais j’espère que je vous aurais motivé à regarder de plus près le DDD. Il y des idées plus qu’intéressantes à appliquer dans vos projets. Le DDD va vous faire réfléchir sur l’architecture de votre code et sur son alignement avec votre business.
Il y a deux livres à lire sur le DDD, le Blue Book et le Red Book. J’ai commencé par le Red Book, car il m’a été livré en premier (le bleu attend sagement sur mon bureau). Visiblement, on peut commencer par l’un ou l’autre, mais le Red Book est un peu plus concret. En tout cas, une lecture plus qu’intéressante, que je ne peux que vous conseiller.